
Speech Recognition by Using Recurrent Neural Networks on Smart Devices for E-Commerce
Tagged: Computer Science
1.0 Introduction
These devices are finding a variety of uses in both the workplace and the home thanks to the development of the Internet of Things (IoT). In reality, the Internet of Things is fueled in large part by voice assistants. Digital purchases are made even simpler by voice-enabled searches, which are highly popular and frequently used for online shopping. A few examples of powerful virtual assistants that are excellent at responding to voice requests include Apple’s Siri, Google Assistant, Samsung’s Bixby, Amazon’s Alexa, and Microsoft’s Cortana. The usage of voice-based search is growing in popularity as a form of communication as it saves users time and effort by removing the need to search for keys or input. Users can use the capability to do a variety of online tasks that would normally require input and progress from them. The fundamental value and contemporary prospects of speech commerce are viewed from a variety of angles, notwithstanding the significant advancements made in recent years by voice activated assistants and the accessories they go with.
AI businesses are already utilizing natural language processing (NLP) to enhance the fundamental communication with these helpers. Voice assistants can communicate with users in natural language and leverage cloud computing to merge AI. Virtual reality, augmented reality, and speech interaction, among other emerging technologies, are changing how individuals engage with the outside world and how they perceive digital encounters. The majority of computing and artificial intelligence processing happens on the cloud instead of on the device itself because a smart speaker is meant to be simple. The basic idea is that the user speaks their request into a speech-activated gadget, which transmits it to the cloud where it is converted to text. This study’s goal is to use recurrent neural networks to improve people’s understanding of phonemes or words (RNN). The text request is sent to the backend after utilizing RNN to convert text from audio, where it is processed and answered with a text response. The text response is then transmitted back to the recipient after being converted to voice in the cloud.
1.1 Aim and Objectives
The research’s goal is to identify voice assistants based on smart gadgets that are utilized for online shopping.
- Finding a good dataset with voice commands text for speech recognition is the primary goal of the project.
- To magnify the inaudible input voice and transform it into a sound wave audible to people with normal hearing.
- To eliminate all noise from the boosted data.
- Using NLP, convert audio recognition through speech, text understanding, and output.
- Perform Recurrent neural network operation on the dataset to convert audio into text.
1.2 Background
Ecommerce has gradually become the preferred purchasing channel for consumers, and voice assistants and other cutting-edge technologies have helped this transition (VA). The market is currently producing a variety of artificial intelligence models, and one of these, the VA, has progressively established itself as a source of information. Smart speakers with voice assistants, like Amazon Echo and Google Echo, provide advantages and convenience, but their ever-listening microphones raise privacy concerns. It is a challenging problem to recognize contact names in mobile voice commands. Potentially endless languages, low connection token likelihood in the language model (LM), enhanced false contact voice command triggering when none are supplied, and extremely big and noisy contact name databases are a few of the problems.
To address the demands of a growing population, innovative technologies are needed. Robot interaction is a method for operating a mobile robot that utilizes Android phones’ voice recognition feature. Controlling a speech-based robot with an Android smartphone while displaying information on speech recognition accuracy for both young and senior users. A piece of Android operating system that analyses speech and translates voice commands into text will be used for speech synthesis. These processed commands are transmitted over Bluetooth to the robot. Due to the nearly limitless potential applications, which span from home appliances to special-purpose systems, voice control system technology has been a focus of research for many years.
Systems that use automatic speech recognition (ASR), such as Google Assistant and Cortana, are very popular. Avoid making unnecessary noises while transmitting voice commands or using ultrasonic speakers. The preliminary assessments of transferability provide us the chance to comprehend user voice and to develop a methodical strategy for transferring the voices in the future. The voice recognition is straightforward and doesn’t need any setup, but it only works for voice signals and doesn’t work for the wider category because the voice is too quiet or unclear. Additionally, all signals, not just voice, can be used to address the greater career of non-linearity speech stream concerns.
2.0 Methodology
2.1 Dataset
The AIY website’s Speech Commands Dataset includes 65,000 utterances of 30 brief words that last one second and come from tens of thousands of users. The work is subject to the Creative Commons Attribution 4.0 International license. With the spoken word audio dataset called Speech Commands can be used to test and improve keyword detection algorithms. There are 105,829 recorded audio of people who are saying a single phrase in every WAV file. To build the train, validation, and test sets, the dataset includes a list of records for validation and testing. The sound files’ minimum size varies from 7K to 32K when a spoken phrase is present, but they can be as large as 3M when background noise is present.
2.2 Data Pre-processing
This essay offers a concept that is simple to analyze and put into practice in the present. A multiplier is needed to boost the voice signals, which were at noticeably lower levels before because of background noise. Speech and noise signals are dynamic, making it difficult to determine a constant multiplication factor (MF) for the incoming signal. As a result, it is necessary to assess the environment’s signal and noise levels. Based on the characteristics of both the speech and noise signals, the strength of the speech signal will be dynamically changing.
The system gives the user the option to say whether or not the MF (auto gain) it generates is acceptable. Such an assumption can typically be easily verified because volume control can be employed for the desired outcome. In the presence of fluctuating background noise, which can also amplify the received speech signal, the gain defines the amplification factor/MF of the speech signal. In this situation, many signal and noise parameters can be used.
This study suggests a technique for overcoming the relative degradation of the voice signal in a noisy setting. Numerous solutions have been developed and put into practice to maintain signal quality in a noisy environment. The human ear will not be able to detect any noise distortion as long as the spatial frequency density of the distortion is smaller than the masking threshold (masking thresholds can be determined using critical zone analysis of the speech signal). As a substitute to the time domain method, the signal’s frequency components can be boosted, bringing the noise level in each important band below the masking limit. As a result, it is necessary to assess the environment’s signal and noise levels.
2.3 Audio Recognition
Instead of utilizing complex computer commands, consumers can interact with devices using their own voice and natural language thanks to natural language processing. Natural Language Processing is used to analyses and convert spoken words into text in a voice-to-text synthesizer (NLP). The text is then converted into a synthetic spoken version of the text utilizing digital signal processing technology. Additionally, voice recognition is performed using a speech recognition library that supports a number of Python engines and APIs.
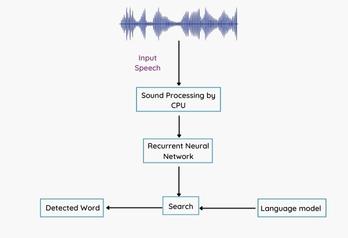
2.4 Recurrent Neural Network
Both audio and visual signals have a specific structure that must be maintained in order to interpret the signal. Recurrent neural networks (RNNs) keep the input structure, in contrast to feed forward neural networks. Speech also has contextual relationships in addition to its fundamental sequential pattern. For such sequential data, RNNs perform well. Recurrent neural networks are used in this domain to benefit from their capacity to handle short-term spectral data while still responding to long-term temporal events. Previous studies have shown that speaker recognition performance increases with utterance duration. Additionally, it has been demonstrated that identifying issues. RNNs have the potential to perform better and learn more quickly than traditional feed forward networks. The hidden layer is fed back to fully recurrent networks. Fully recurrent networks are the foundation of partially recurrent networks, which then add a feed forward link to avoid the recurrence and employ the recurrent portion as a state memory. Due to their limitless memory depth, recurrent networks may identify relationships in both the instantaneous input space and time. The time structure of most real-world data provides information. The most advanced method for nonlinear time series forecasting, system identification and categorization of temporal patterns is recurrent networks.
2.5 Summary
Based on the kinds of sounds they can recognize, speech recognition systems are categorized into a wide range of various subcategories. Python uses a speech recognition package to identify the process. These courses are based on the concept that one of the trickiest parts of ASR is figuring out when a speaker starts and stops iteration. The audio to text capability is then built using cutting-edge RNN algorithms. Future versions of ecommerce’s Auto Update Cart, which enables customers to change the quantity of an order and immediately have the cart update to reflect the new quantity, may employ speech recognition.